
The following is Chapter 7, Section 3, from the book The Techno-Humanist Manifesto by Jason Crawford, Founder of the Roots of Progress Institute. The entirety of the book will be published on Freethink, one week at a time. For more from Jason, subscribe to his Substack.
In Section 1 of this chapter, we argued that physical resources are not a barrier to progress. In Section 2, we argued that progress will also not be stalled by a lack of ideas, or by fishing all ideas out of the idea pond.
Through all of these purported barriers to progress—from resource depletion to using up low-hanging fruit to population decline—there runs a theme.
Every prediction of stagnation points at some problem and claims, implicitly or explicitly, that we won’t solve it. Often this rests on an argument that some trend can’t continue forever—the growth of agriculture, the extraction of fossil fuels, the progress of Moore’s Law, whatever.
This type of claim feels like an intelligent, sober, rational analysis. It is grounded in facts and data, based only on what we can observe and predict. It is the opposite of wild-eyed speculation or fantasy. And at some level these claims are true. No trend can continue forever.
Any given oil field will peak and decline. Sustained growth in oil production comes from finding new fields, and sometimes from inventing entirely new techniques, such as fracking.
Every technology follows an S-shaped curve: ramping up exponentially at first, then leveling off as it reaches its potential. Sustained progress comes from “stacking S-curves”: whenever one technology starts to plateau, we transition to a new one. Thus we advanced from the water wheel to the steam engine to the internal combustion engine to the gas turbine.
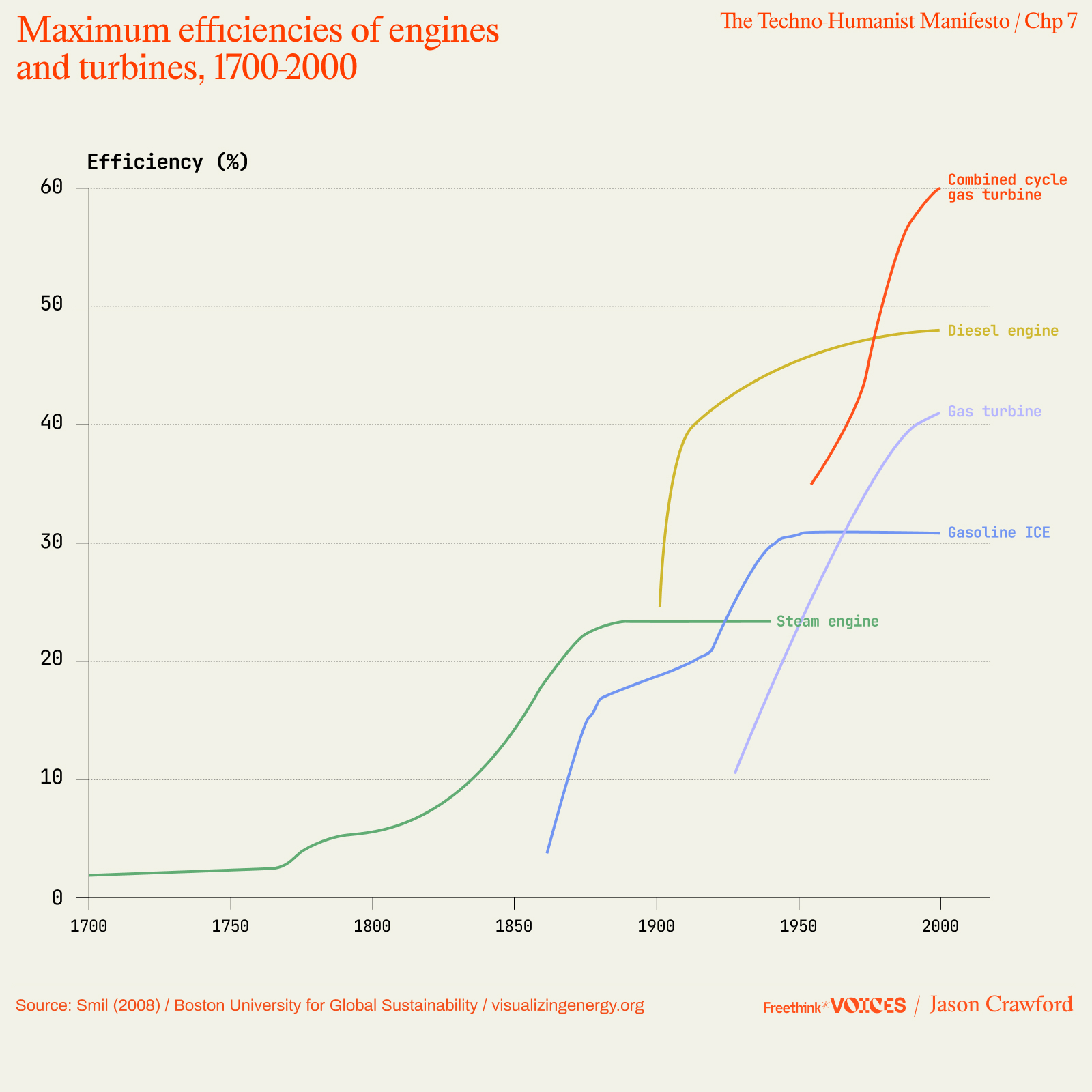
No proven resources or technologies can sustain economic growth. The status quo will plateau. To expect growth is to believe in future technologies. To expect very long-term growth is to believe in science fiction.
No known solutions can solve our hardest problems—that’s why they’re the hardest ones. And by the nature of problem-solving, we usually discover problems before we discover their solutions. So there will always be a frontier of problems we don’t yet know how to solve.
To believe we can somehow make trends continue, past the point where anyone can see exactly how this is possible, requires believing in an unknown solution—the next oil field, or the next innovation—arriving seemingly from out of nowhere, and just in the nick of time. It requires believing that at least some current wild-eyed speculation will come true.
This feels like blind optimism or even wishful thinking—naive, immature, irresponsible. And yet, over the long run of history, “blind” optimism would have been a better predictor than “sober” pessimism of what has actually happened. We did find the next oil field, the next alloy, the next type of engine, the next variety of wheat, the next antibiotic, and a thousand other solutions.
Believing in the next solution is not blind, nor is it a denial of the problems we face. It is a recognition of a much more profound and powerful truth: we are problem-solving animals. Problem-solving is fundamental to human nature.
The proof is in our track record: both the length and the breadth of our history of problem-solving. The length is what we saw in the previous chapter: a consistent pattern of accelerating growth across millions of years. But we should also appreciate the breadth of problems that we have solved. Our success is not due to one resource, such as fossil fuels, or even to one technology, such as energy. We have solved problems in materials, mechanical engineering, and precision manufacturing; the growth of crops and the production of chemicals; the organization of factories and the management of teams. We discovered how to find our way at sea and how to turn our thoughts into electricity. We discovered how to sanitize our food and water and how to supercharge our immune systems against disease. We discovered how to predict the weather and how to make our buildings withstand earthquakes.
This was not a fluke. We did not get lucky. We are problem-solving animals.
Our problem-solving ability is based on two deep and powerful facts. The first is that reality contains a vast space of possibilities in which to search for solutions. This is because the possibility space is combinatorial: new possibilities are created from the combination of simple elements. And combinations grow very quickly.
Suppose we are hunting for new drug molecules. Molecules are combinations of atoms, and there are many types of atoms, and many ways to combine them, even if we exclude large biological molecules or polymers. The number of possible small molecules has been estimated in excess of 1060, an astronomical figure.1 For comparison, comprehensive databases of known chemicals, such as the NIH’s PubChem or the American Chemical Society’s CAS Registry, contain a mere ~108 entries.2 That’s not a drop in the bucket; that’s a molecule of water in a hundred thousand oceans.3
Or suppose we are engineering proteins. The number of amino acid sequences of modest length, say 300, is about 10390.4 By one estimate, only perhaps 1 in 1011 of these are functional proteins; that still leaves 10379.5 To call this “astronomical” would be an absurd understatement; it is closer to an astronomical figure raised to the fifth power. Again, for comparison, the UniProt database of known proteins contains only ~108 entries.6
Or suppose we are optimizing a simple microbe—say brewer’s yeast, Saccharomyces cerevisiae. The yeast genome has about 12 million base pairs. The number of DNA sequences of that length is ~107,224,720. But most of those aren’t even viable genomes, and most of the viable ones aren’t yeast, so let’s use a much more conservative estimate. One survey of over 3,000 yeast genomes found 1,918,693 locations where a significant fraction of genomes differed—known as single nucleotide polymorphisms, or SNPs—and that any two cells differed in about 52,000 locations.7 Each of these variations is thus a viable option for a yeast cell, and they can be combined. Thus there are probably at least 21,918,693 = ~10577,584 viable yeast genomes. This is a number that defies description. The human genome is 3 billion base pairs, with over 600 million known SNPs; making the corresponding numbers that much larger.8

These examples are based on atoms, but the same combinatorial explosion happens with information. Counting the valid computer programs with up to a million lines of code, or the neural networks with a trillion parameters, would produce numbers that are even more unfathomable.9 And remember that social institutions, such as a code of law or a moral philosophy, are also information—which means they too have a combinatorially large possibility space, out of which very, very little has even been conceived, and still less has been tried.
In short: We have not yet begun to explore.
Fantastic things could be lurking in unexplored possibilities. Paul Romer suggests:
[I]magine the ideal chemical refinery. It would convert an abundant, renewable resource into a product that humans value. It would be smaller than a car, mobile so that it could search out its own inputs, capable of maintaining the temperature necessary for its reactions within narrow bounds, and able to automatically heal most system failures. It would build replicas of itself for use after it wears out, and it would do all of this with little human supervision. All we would have to do is get it to stay still periodically so that we could hook up some pipes and drain off the final product.
This refinery already exists. It is the milk cow. Nature found this amazing way to arrange hydrogen, carbon, and a few other miscellaneous atoms by meandering along one particular evolutionary path of trial and error (albeit one that took hundreds of millions of years). Someone who had never heard of a cow or a bat probably would not believe that a hunk of atoms can turn grass into milk or navigate by echolocation as it flies around. Imagine all the amazing things that can be made out of atoms that simply have never been tried.10
The problem with such a vast space is that it is impossible to search via simple enumeration. Consider again the set of small molecules. Just as a thought experiment, to get a sense of scale: imagine you turn every man, woman and child on Earth into a biochemical researcher (~1010). Give an entire planet full of such researchers to every star in the galaxy (1011).11 Repeat for every galaxy in the observable universe (another 1011).12 That’s 1032 researchers. Give each of them equipment that can test out one small molecule per nanosecond (more than 1016 per year). Even with this fantastic scientific endowment, to cover 1060 molecules would take over a hundred billion years—many times the age of the universe. And remember that this was by far the smallest possibility space calculated above. To cover even all proteins, let alone all genomes, etc., would be simply impossible.
The saving grace is that the possibility space is not random: it has structure, and the structure can be exploited for efficient search.
First, viable solutions are often adjacent. A molecule with one side chain added can be another interesting molecule; a protein with one amino acid changed can be another functional protein; a genome with one gene inserted can be another viable genome. This means that starting from something that works, it’s possible to explore other solutions by changing one thing at a time. This is how evolution has proceeded for billions of years.
But that evolution has now produced us, beings with a symbolic intelligence. And that brings us to the second key fact: human intelligence can understand the structure of reality, to produce a search that is much more efficient than random variation and natural selection.
Consider ML01, the first genetically engineered yeast used in the wine industry. Natural yeast produces malic acid during fermentation. To remove the sour taste of this acid, winemakers traditionally used a bacterial species, Oenococcus oeni, to turn malic acid into milder lactic acid. But using O. oeni was slow, unreliable, and created toxic byproducts. ML01 contains the malolactic enzyme from O. oeni, and a transport gene from another strain of yeast, in order to process the malic acid itself—no bacteria required.13 This is evidently one of the possible yeast genomes, and not even one of the 10577,584 we counted above, since it requires not just varying SNPs but inserting entire genes.
This yeast would never have been created by nature, but it was discovered by human intelligence. Intelligence was needed to understand different types of acids, and enzymes that can convert between them; to identify the gene for one enzyme among over a thousand genes in one species of bacteria; to devise tools to cut and paste genes from one microbial species to another; to found research institutions where people can focus on such specialized, abstract tasks and integrate them into the world economy; to establish a patent system that enables such research to be funded; to formulate a scientific epistemology to guide those researchers in their work and a philosophy of progress to motivate and inspire them.
In sum: The combinatorial vastness of possibility space means that solutions are out there. The structure of that space, and the power of intelligence to navigate it, means that we can find them.
When you hear an argument that progress cannot or should not continue, try framing it as a claim that a certain problem can’t be solved. Thus, fears of resource depletion become a claim that we can’t find new reserves or switch to more abundant resources. Much of environmentalism becomes a claim that we can’t clean up pollution, patch the ozone hole, or stabilize the climate. Moral objections to social media are claims that we can’t solve problems of addiction and build a healthy relationship with our technology.
This framing is powerful. It helps us avoid defeatist pessimism, in which we claim that these problems are impossible to solve, and also complacent optimism, in which we ignore, downplay or deny the problems. It helps us reframe the discussion in more productive terms: about how to solve them, how much investment that will take, and which problems deserve more attention.
Framing progress as a product of human problem-solving also puts our focus on agency, rather than luck. This is crucial. If the progress of the last few centuries was a random windfall, then pessimism is logical: our luck is bound to run out. How could we get that lucky again? Growth was slow for most of human history, so if the next century is an average one, it will see little progress.
But progress was not a windfall. Resources did not find us. We found them. Ideas did not write themselves into our books. We invented them. Progress did not happen to us. We made it. And we can continue to do so.
1: Bohacek et al., “The Art and Practice of Structure-Based Drug Design;” see footnote at the bottom of p. 43.
2: “PubChem Data Counts”; “CAS Registry.”
3: The volume of all of Earth’s oceans is around 1.3 billion km3: “How Much Water is in the Ocean?” Based on the density and molar mass of water, this gives an estimate, rounding to the nearest order of magnitude, of 1047 water molecules in the ocean. 105 of these gets us the ratio between PubChem and all possible chemicals.
4: 300 amino acids is a typical human protein length: Fields and Johnston, “Proteins are the Workhorses of the Cell.”
5: Keefe and Szostak, “Functional Proteins from a Random-Sequence Library.”
6: “UniProt.”
7: Loegler, “Overview of the Saccharomyces Cerevisiae Population Structure.”
8: “What Are Single Nucleotide Polymorphisms?”
9: These are typical sizes, or even underestimates, for a large codebase or LLM. Tyson, “Linux Kernel Source Expands Beyond 40 Million Lines”; “Parameters in Notable Artificial Intelligence Systems.”
10: Romer, “The Deep Structure of Economic Growth.”
11: “How Many Stars in the Milky Way?”
12: Saunders, “How Many Galaxies Are in the Universe?”
13: Husnik, “Metabolic Engineering of Malolactic Wine Yeast.”





