
The public version of OpenAI’s ChatGPT recently gained “multimodal” capabilities, meaning it can now not only do text but also analyze images, interpret and produce speech, browse the internet, and scan the content of uploaded files.
Still, ChatGPT operates in a mostly siloed fashion. It can’t yet venture out “into the wild” to execute online tasks. For example, if you wanted to buy a milk frother on Amazon for under $100, ChatGPT might be able to recommend a product or two, and even provide links, but it can’t actually navigate Amazon and make the purchase.
Why? Besides obvious concerns, like letting a flawed AI model go on a shopping spree with your credit card, one challenge lies in training AI to successfully navigate graphical user interfaces (GUIs), like your laptop or smartphone screen.
But even the current version of GPT-4 seems to grasp the basic steps of online shopping. That’s the takeaway of a recent preprint paper in which AI researchers described how they successfully trained a GPT-4-based agent to “buy” products on Amazon. The agent, dubbed the MM-Navigator, did not actually purchase products, but it was able to analyze screenshots of an iOS smartphone screen and specify the appropriate action and where it should click, with impressive accuracy.
AI and GUI navigation
An Yan, an AI researcher at UC San Diego and an author of the recent paper, told Freethink there are two main challenges in training large-language models like GPT-4 to navigate GUIs.
The first is getting the model to describe the appropriate action, which it does through semantic reasoning. For example, if you give GPT-4 a screenshot of your iOS smartphone screen and ask it to select the most appropriate app for buying a milk frother online, it’ll have an easy time choosing Amazon.
“The whole semantic screen understanding stuff — I would say it’s almost perfect,” Yan told Freethink.
The bigger problem lies in a different type of understanding: where to click.
“That part is a bit more challenging,” Yan told Freethink. “[GPT-4] is not so good at numerical-spatial reasoning.”
Yan and his colleagues had tried asking the agent to analyze a phone screen which had a grid of numerical coordinates overlaid on it, like latitude and longitude lines on a map, and pick coordinates that aligned with the button it wanted to click. It often failed to pick accurate coordinates.
With a little help, however, MM-Navigator was able to boost its so-called localized action execution skills in order to “buy” products on Amazon. After the researchers attached numerical markers to the various apps and buttons on the smartphone screen, which narrowed the options of where the agent could click, MM-Navigator specified the correct location with an accuracy of 74.5% across 55 test runs.
Those test runs were structured in a surprisingly straightforward fashion, though they included a clever trick that potentially increased the agent’s success rate by simulating something like the short-term memory of the human brain.
Historical context
In one set of experiments, the researchers gave the agent a simple prompt and a screenshot of an iOS smartphone screen, pictured below.
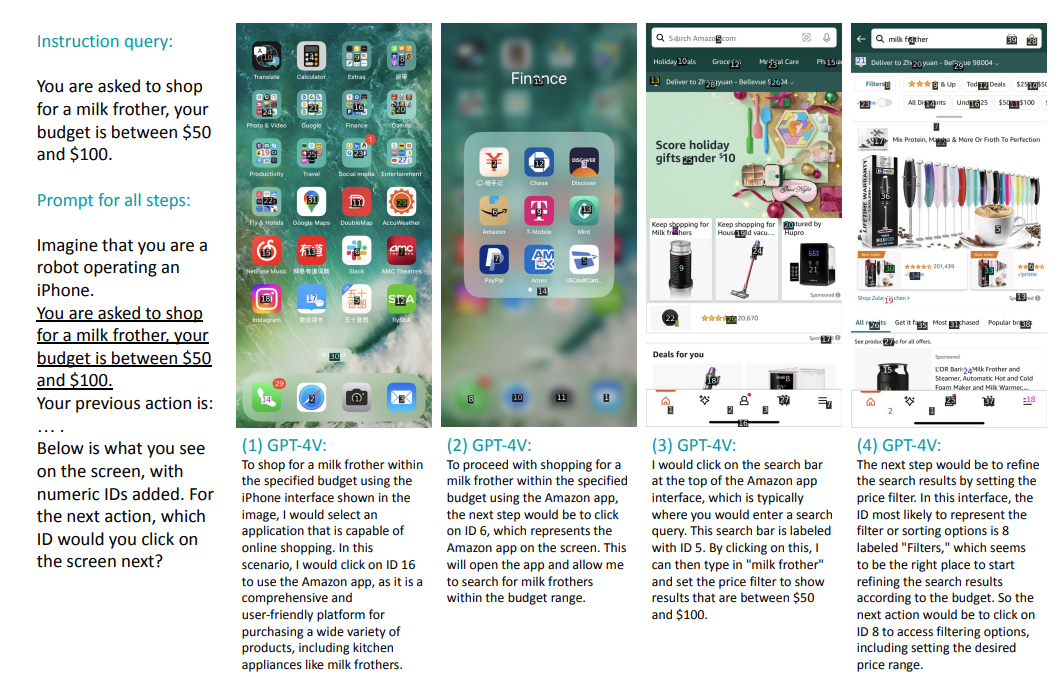
At each step, the agent was shown the screenshot that would be displayed based on the button it selected. Importantly, however, the agent was programmed to briefly summarize both its current suggested action and the actions it’s already taken to get to that point. The goal, Yan said, is to “somehow encourage this model to think more like a human.”
When you’re buying something online, for example, your short-term memory automatically keeps track of recent actions and pages you visited. But you only remember the key information. After all, it’d be difficult and mostly useless to remember every bit of text and visual information that was on every page that led you to click “buy” on a page for a milk frother.
Similarly, it’d be computationally expensive, and wasteful, to have an AI record and recall every single bit of information as it’s navigating the internet. There’s also a more fundamental problem with current large-language models, which is that their memory remains imperfect. So, Yan and his colleagues programmed the AI to behave like a human: memorize only the crucial bits and summarize them in plain language at each step.
“History is how a model can act as a human — as an agent,” Yan told Freethink. “This is really a short-term memory.”
MM-Navigator still made mistakes in the recent study, most of which occurred during localized action execution as opposed to intended action description. Yan said it will take further research to uncover exactly why large language models make certain mistakes and how they might be prevented.
“How does a model realize it makes mistakes and [how does it correct its actions]? That’s definitely interesting.”
MM-Navigator was not intended to be a product but rather a foundation on which researchers can improve how AI models navigate and interact with our existing technology. As for how long it will be until getting an AI to do multistep online tasks is as easy as speaking a few words?
“I don’t want to create a hype here, but maybe one or two years,” Yan told Freethink. “Unless some startup is [already] trying to beat Apple’s Siri.”





