This article is an installment of Future Explored, a monthly guide to world-changing technology. You can get stories like this one straight to your inbox every month by subscribing above.
It’s 2040. Drug discovery is booming, thanks to virtual cells. These AI-powered models of living cells have become indispensable tools in biomedical research, helping scientists test treatments in silico before they ever reach a lab — saving time, money, and lives.
Virtual Cells
Artificial intelligence is quickly becoming biology’s most powerful microscope.
Top research centers are using the tech to develop virtual cells, AI-based simulations of the core building blocks of all lifeforms — and it’s hard to overstate the impact their models could have on the world of health.
“The vision that we can really understand everything about a cell — from its molecular structure to its function to how cells interact and operate in living organisms to how they respond and react to any intervention — will go a long way to helping us cure, prevent, and manage disease,” said Patricia Brennan, VP of Science Technology and General Manager for Science at the Chan Zuckerberg Initiative (CZI).
To find out how we got here — and where we’re going — this month’s Future Explored is taking a close look at virtual cells: what they are, who’s making them, and how they could shape the future of medicine.
Where we’ve been
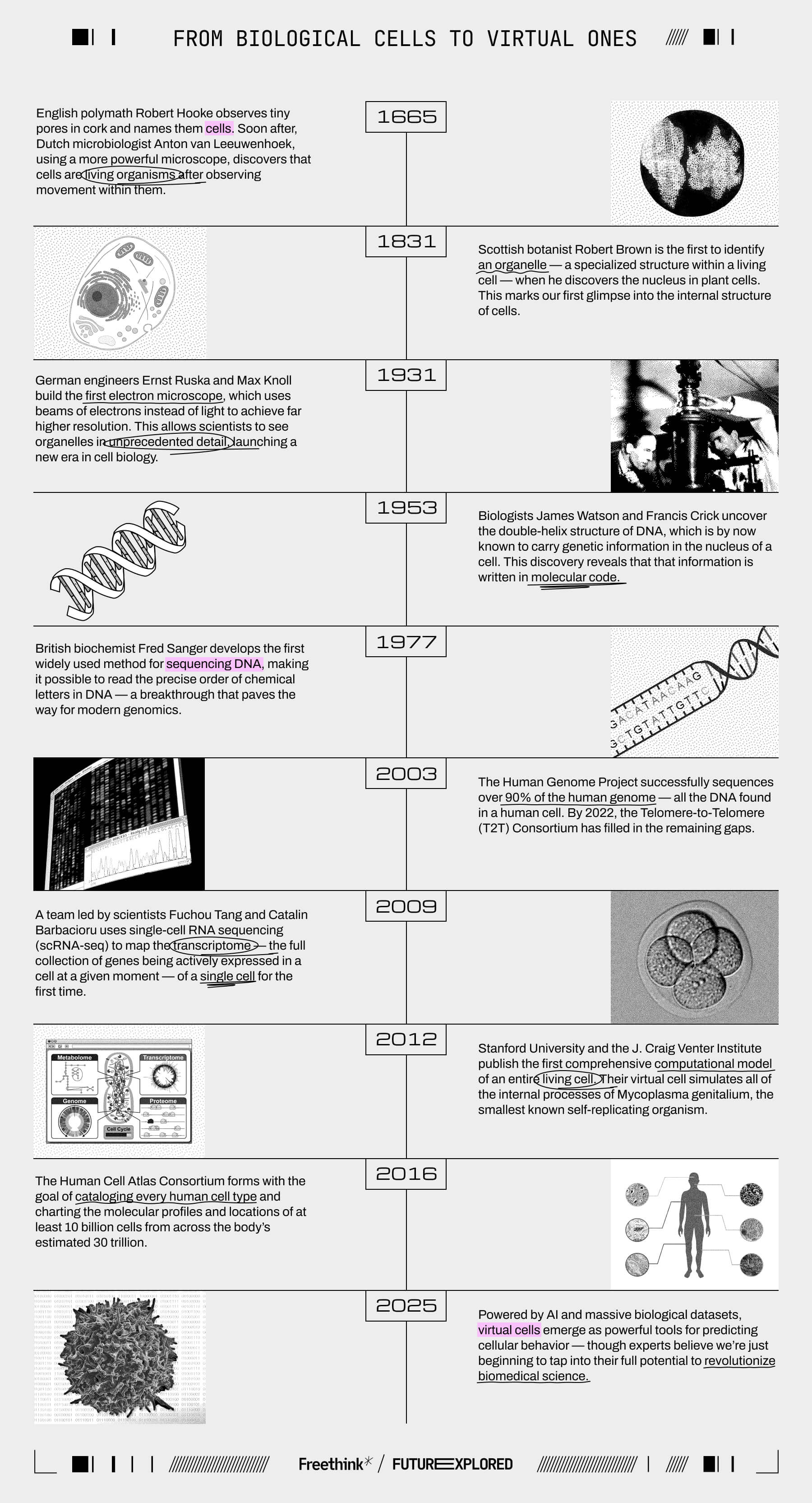
Where we’re going (maybe)
The first virtual cell was built over a decade ago — so why is interest in them surging now? The answer lies in fundamental differences in how today’s models work compared to ones like what the Stanford team created in 2012.
Their virtual cell simulated all of the molecular processes of Mycoplasma genitalium (Mgen) by breaking them into 28 modules, each governed by its own set of mathematical equations and biological rules — a simplified example might be, “If Gene A is expressed, Gene B will be activated.”
The team developed those instructions by painstakingly digging through more than 900 papers, books, and databases, essentially distilling all of the scientific community’s knowledge of how Mgen functions into 28 algorithms. Once complete, their model could simulate the entire Mgen lifecycle, from birth to division, in about 10 hours — roughly the same amount of time an actual Mgen cell takes to divide.
Simply being able to observe this process was valuable, but the real utility of the virtual cell was that researchers could experiment on it. They could knock out a gene with keystrokes instead of CRISPR and then run the simulation to predict how its loss would affect Mgen. If they saw something interesting, they could then spend time on a lab experiment.
“If you use a model to guide your experiments, you’re going to discover things faster,” said study leader Markus Covert in 2012. “We’ve shown that time and time again.”
Most of the time, the virtual cell’s predictions would match the results of real-world experiments. When they didn’t, the discrepancies usually involved genes that were poorly understood in scientific literature. That made sense: The model was limited by its programming. If scientists wanted to improve it, they’d need to update their algorithms.
“If you use a model to guide your experiments, you’re going to discover things faster.”
Markus Covert
In the years following the Stanford breakthrough, other groups made their own virtual cells using the same method: distill the known literature into rule-based algorithms.
Today’s virtual cells, however, are built on artificial intelligence, usually a specific kind of model called a transformer. Google researchers first proposed this AI architecture in 2017, and it’s the basis for many of today’s best generative AIs, including ChatGPT.
Transformer-based AIs learn to spot relationships between tokens (small units of data) by training on huge datasets. Once trained, they can then generate new content by predicting the most likely next token in a sequence.
For ChatGPT, for example, tokens are words or parts of words. The huge training dataset was the internet, and once trained, ChatGPT was able to generate text by predicting the most likely token to come next in its response, over and over again, based on the ones that came before it.
One of the most remarkable things about transformer-based AIs is that they can output content that isn’t included in their training data. An AI image generator, for example, can output a photorealistic picture of a cat made of spaghetti even if it wasn’t explicitly shown what that should look like.
“The goal is for virtual cell models to serve as digital twins or computational stand-ins for experimental systems.”
Marinka Zitnik
Researchers are now building virtual cells on the transformer architecture — and the results are remarkable.
CZI’s TranscriptFormer model, for example, was trained on datasets containing images, RNA sequences, and other biological data from 112 million cells. These were drawn from 12 different species across 1.5 billion years of evolution. A researcher can now prompt it with data from a cell they’re studying, and the AI can predict its cell type, infection status, and more — even if the cell comes from a species that wasn’t included in the model’s training data.
“We just trained it on natural variability, but this natural variability follows the tree of life: It has a lot of structure. There’s a lot of interesting stuff happening there,” said Theofanis Karaletsos, Senior Director of AI at CZI. “The model actually becomes extremely rich and extremely performant on doing all kinds of tasks.”
CZI is now offering researchers early access to a one-stop platform that includes several virtual cell models, including TranscriptFormer, and the datasets used to train them. These models have specific use cases — CZI’s GREmLN model, for example, predicts how genes work together — but the vision is to develop models that can simulate more complex cellular behavior.
“Looking forward, the goal is for virtual cell models to serve as digital twins or computational stand-ins for experimental systems,” said Marinka Zitnik, a CZI collaborator and assistant professor at Harvard. “For example, a validated virtual cell could simulate the outcome of a drug or genetic intervention in silico, potentially reducing the need for animal experiments or guiding the design of laboratory studies.”
“You ask the model, ‘What perturbations do I need to make to move this cell from this diseased state to this healthy state?’”
David Burke
Biomedical research nonprofit Arc Institute is building virtual cells, too. It recently opened access to its first model, STATE, which was trained on observational data from nearly 170 million cells and perturbational data from over 100 million cells. Perturbational data captures how a cell reacts when its normal function is disrupted by a drug, genetic edit, or some other external stimulus.
Researchers input a cell’s transcriptome — the full collection of genes being actively expressed at a given moment — and a proposed perturbation, and STATE predicts how the cell’s gene expression patterns are likely to change. This can give scientists a way to test the potential impact of disease treatments without having to actually perform experiments.
By running this process in reverse, STATE can even point researchers toward promising interventions they hadn’t considered.
“You take a cell that’s in a diseased state — like maybe it’s got an Alzheimer’s disease transcriptomic profile — and one in a healthy state, and then you ask the model, ‘What perturbations do I need to make to move this cell from this diseased state to this healthy state?’” said David Burke, Arc Institute’s CTO.
STATE’s predictions range in accuracy from 40% to 60%, depending on the type of perturbation, according to Burke. He thinks 75% would be good enough that biologists could start relying on the AI’s predictions without having to run experiments in the wet lab.
“That might seem a bit low,” said Burke, “but when you look at all the different datasets from different labs, the concordance between them is only about 75% because single-cell sequencing and perturbation screens are very noisy, so that’s our target.”
“We will need a lot more data.”
Patricia Brennan
A transformer model is only as good as the quality and quantity of its training data, so if we want to improve today’s virtual cells, we’re going to need to improve our datasets.
“While the scale of the data sets has been growing over the last number of years, we will need a lot more data,” said CZI’s Brennan, who noted that much of the data we already have wasn’t necessarily collected with the training of virtual cells in mind, which complicates its use as training material.
To help close the data gap as quickly as possible, CZI launched the open-source Billion Cells Project (BCP) in February. The goal of the initiative is to quickly and cost-effectively generate a public dataset containing one billion cells through partnerships with scientists and the developers of cutting-edge cell analysis technologies.
“Traditional data generation pipelines can take three to four years, whereas BCP is compressing that timeline to months,” said Bailey Marshall, Senior Program Associate, Single-Cell Biology at CZI.
“One of the project’s most important innovations is in interoperability,” she added. “By aligning from the outset on standardized kits, protocols, and technologies across the BCP…data from diverse tissues, species, and modalities can be easily integrated. This allows researchers and AI developers to train models that are consistent, reproducible, and broadly applicable.”
“How far can we go? That’s an open scientific question.”
David Burke
So, in the short term, the scientific community knows it needs more data to make its virtual cells more robust, but the extent to which it can improve them is still unknown.
With enough high-quality data, is it possible to make a single model that accurately predicts everything that will happen in a cell when it’s perturbed in every way possible? How about a model that takes into account how cells work in context with one another? Can we create virtual models of entire tissues, organs, or even bodies?
If so, it would mark a turning point in biology — moving from a science that observes life to one that can simulate and predict it. The consequences for medicine, longevity, and our understanding of health would be transformative.
“How far can we go? That’s an open scientific question,” said Burke.
We’d love to hear from you! If you have a comment about this article or if you have a tip for a future Freethink story, please email us at [email protected].